推荐系统常用技术&架构
因为在业界带来了巨大的用户体验价值和商业价值,最近10年推荐系统在互联网系统应用的越来越广泛。 同时因为推荐系统是一个复杂的系统工程,各个公司算法/策略都是五花八门,同时也因为新的机器学习技术的应用,推荐系统方案也是在不断演进。 本文主要总结业界目前常用的技术/架构,是为对本人自身的经验总结,也希望这方面的初学者能够得到借鉴。
系统架构
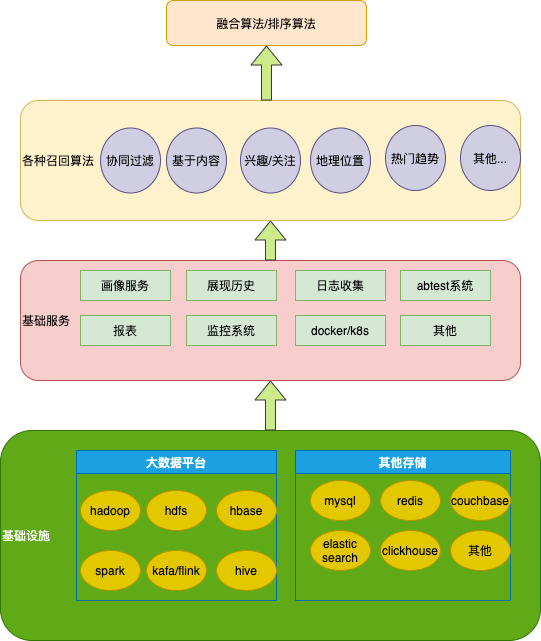
召回算法
在推荐系统中,会面临很多不同的需求, 例如在电商/或者资讯系统中,用户可能希望看到,以下内容:
- 当前热门内容,或者热门新闻 (基于内容)
- 和我浏览历史相关的内容(itemcf),或者和我自身相似用户目前正在看的内容(usercf)
- 为了平台的更好商业化,或者更好引导用户,平台会设置一些规则,优先向用户展示一些内容(如:低俗打压,人工运营内容等)
- 结合1和2,推荐即符合内容相关性,又符合用户历史行为的的相关性,例如:用户历史行为分析直到用户体育新闻, 那么就优先推荐体育类的新闻,再从用户历史行为看,用户可能更喜欢篮球方面的内容,那么篮球方面的新闻应该具有更高优先级(混合模型: 用户/物品画像,用户行为)
- 其他
面对项目几种不同的情景/需求,通常我们会将整个推荐系统分割成两个召回层和融合层,用单个召回来实现不同的推荐需求,然后再融合层通过一定的方式重新排序整合输出的用户端。 下面解释集中常用召回算法具体实现方式。
基于内容
基于内容的推荐算法,历史最为久远,最简单的实现可能类似与搜索引擎。 例如: 可以将物品的文字描述存储的到搜索引擎中,然后根据用户需要的关键字,进行搜索,同时也可以进行一些其他属性的微调排序
经典的搜索引擎都是直接通过tf-idf之类的模型进行词权重的计算来进行搜索,但是这样的实现的功能还很简单,不够智能。 随着NLP技术的发展,LDA主题模型,word2vec/doc2vec/bert向量模型,在推荐系统中目前已经普遍运用。
协同过滤
协同过滤算法是推荐系统的成名算法,从根本上来说是通过学习用户的历史行为,获得用户/物品的潜在属性(FM因式分解法)。 得到了用户/物品的向量属性,会有两种推荐策略:
- itemcf 基于item相关性
- usercf 基于用户相关性
目前效果上来看,大部分时候itemcf>usercf, 原因可能是用户更关注但前浏览内容的相关性,实时性更高,和用户的近期兴趣更贴合。
(大规模协同过滤算法训练,可以采用spark ml 的als)
基于知识/规则
根据人的先验知识,或者公司的产品调性,人为的干预内容的输出。 不同业务场景,可以根据自身业务特点设计推荐算法,市面上的推荐算法/策略也是千差万别,归根到底都是为了向用户推荐用户感兴趣的内容,或者人为的运营推广。
混合模型
混合模型一般指的是结合用户/物品的画像和用户历史行为,用户/物品/属性的隐藏向量,学习可以理解成进阶的协同过滤算法。常见的实现模型有: FM/FFM,wide deep, deepFM等。
混合模型是目前的主流方法,比单纯的协同过滤算法效果更好,但是也需要另外的特征工程,需要采集到用户/物品合适的特征属性,以及合适特征工程方法。
召回服务实现
拿典型的机器模型模型来说,一般我们会得到用户/物品的embedding信息,然后根据近邻算法排序物品,返回topk的最相关物品。
离线学习
模型的训练一般是定时执行,然后更新的。但是用户/物品的embedding是可以做到实时更新的,部分模型支持根据最新的画像属性生成embedding。
在线服务
在线服务是直接接受用户请求,返回推荐物品的服务。实现上可以是基本的knn算法,同时结合业务需求做一些干预,例如历史内容消重。
(普通的knn算法计算量太高,可以近似优化算法,可以参考annoy等其他算法)
混合排序/融合层
融合层是为了整合推荐系统的各个算法然后重排序返回给用户,因此根据系统的实际需求有不同的实现方式,常规的有以下几种:
- gbdt 集成学习
- ranking算法
- 人工规则
实际上对于1和2来说,多数情况下还是会结合3来设计融合层,因为推荐系统难免有人工干预的情况,不可能完全由机器学习算法取代。
abtest
推荐系统是一个在线系统,因此在任何升级改动时,都需要小批量验证后才能上线,同时abtest系统也广泛使用在其他软件系统中。